
何时优先选择哈希表
- 数据量大且操作频繁,对性能要求高。
- 键分布未知或非常稀疏,无法用一块连续数组高效表示。
- 不需要对键进行排序或范围操作。
- 内存和性能开销可接受哈希函数计算及冲突处理。
特殊情况:
- 当键紧密且连续时,适合直接寻址表,即准备一个和键的定义域一样大的数组,通过一个简单的函数将键一一对应到数组序号
- 当需要键有序时,适合使用基于二叉搜索树的数据结构,比如
std::map
头文件依赖:
c
<unordered_map> -> <bits/unordered_map.h> -> <bits/hashtable.h>unordered_map
以下是<bits/unordered_map.h>中unordered_map模板类的部分源码,注释已经翻译
c++
/**
* @brief 一个由唯一键组成的标准容器(每个键值最多只包含一个),
* 并将另一种类型的值与这些键关联起来。
*
* @ingroup unordered_associative_containers
* @headerfile unordered_map
* @since C++11
*
* @tparam _Key 键对象的类型。
* @tparam _Tp 映射对象(即与键关联的值)的类型。
* @tparam _Hash 哈希函数对象的类型,默认为 hash<_Value>。
* @tparam _Pred 判断两个键是否相等的谓词函数对象类型,默认为 equal_to<_Value>。
* @tparam _Alloc 分配器类型,默认为 std::allocator<std::pair<const _Key, _Tp>>。
*
* 容器的最终值类型是 std::pair<const _Key, _Tp>。
*
* 基类为 _Hashtable,通过模板别名 __umap_hashtable 在编译时进行分发。
*/
template<typename _Key, typename _Tp,
typename _Hash = hash<_Key>,
typename _Pred = equal_to<_Key>,
typename _Alloc = allocator<std::pair<const _Key, _Tp>>>
class unordered_map
{
typedef __umap_hashtable<_Key, _Tp, _Hash, _Pred, _Alloc> _Hashtable;
_Hashtable _M_h;
...
std::pair<iterator, bool>
insert(const value_type& __x)
{ return _M_h.insert(__x); }
...
iterator
erase(const_iterator __position)
{ return _M_h.erase(__position); }
...
}可以看到类内部包含了一个成员_Hashtable _M_h;,类的方法都是基于该成员实现的。_Hashtable的定义位于<bits/hashtable.h>
_Hashtable
以下是部分源码和注释翻译:
c++
/**
* 主类模板 _Hashtable。
*
* @ingroup hashtable-detail
*
* @tparam _Value 可拷贝构造的类型。
*
* @tparam _Key 可拷贝构造的类型。
*
* @tparam _Alloc 分配器类型(参见 [lib.allocator.requirements]),
* 其 _Alloc::value_type 应为 _Value。
* 作为标准扩展,我们允许 _Alloc::value_type != _Value。
*
* @tparam _ExtractKey 函数对象,接收一个 _Value 类型的对象并返回 _Key 类型的值。
*
* @tparam _Equal 函数对象,接收两个类型为 _Key 的对象,返回一个类似布尔值的结果,
* 如果两个对象被认为相等,则返回 true。
*
* @tparam _Hash 哈希函数。一个一元函数对象,其参数类型为 _Key,返回值类型为 size_t。
* 返回值应在整个范围 [0, numeric_limits<size_t>::max()] 上分布。
*
* @tparam _RangeHash 范围哈希函数(按照 Tavori 和 Dreizin 的术语)。
* 一个二元函数对象,其参数类型和返回值类型均为 size_t。
* 给定参数 r 和 N,返回值应在范围 [0, N) 内。
*
* @tparam _Unused 未使用。
*
* @tparam _RehashPolicy 控制桶数量的策略类,包含三个成员:
* - _M_next_bkt(n):返回一个不小于 n 的桶数量;
* - _M_bkt_for_elements(n):返回适用于 n 个元素的桶数量;
* - _M_need_rehash(n_bkt, n_elt, n_ins):判断在当前桶数量为 n_bkt、
* 元素数量为 n_elt 时,是否需要为接下来的 n_ins 次插入增加桶数量。
* 如果需要,返回 make_pair(true, n),其中 n 是新的桶数量;
* 如果不需要,返回 make_pair(false, <任意值>)。
*
* @tparam _Traits 编译时类,包含三个布尔值的 std::integral_constant 成员:
* - __cache_hash_code
* - __constant_iterators
* - __unique_keys
*
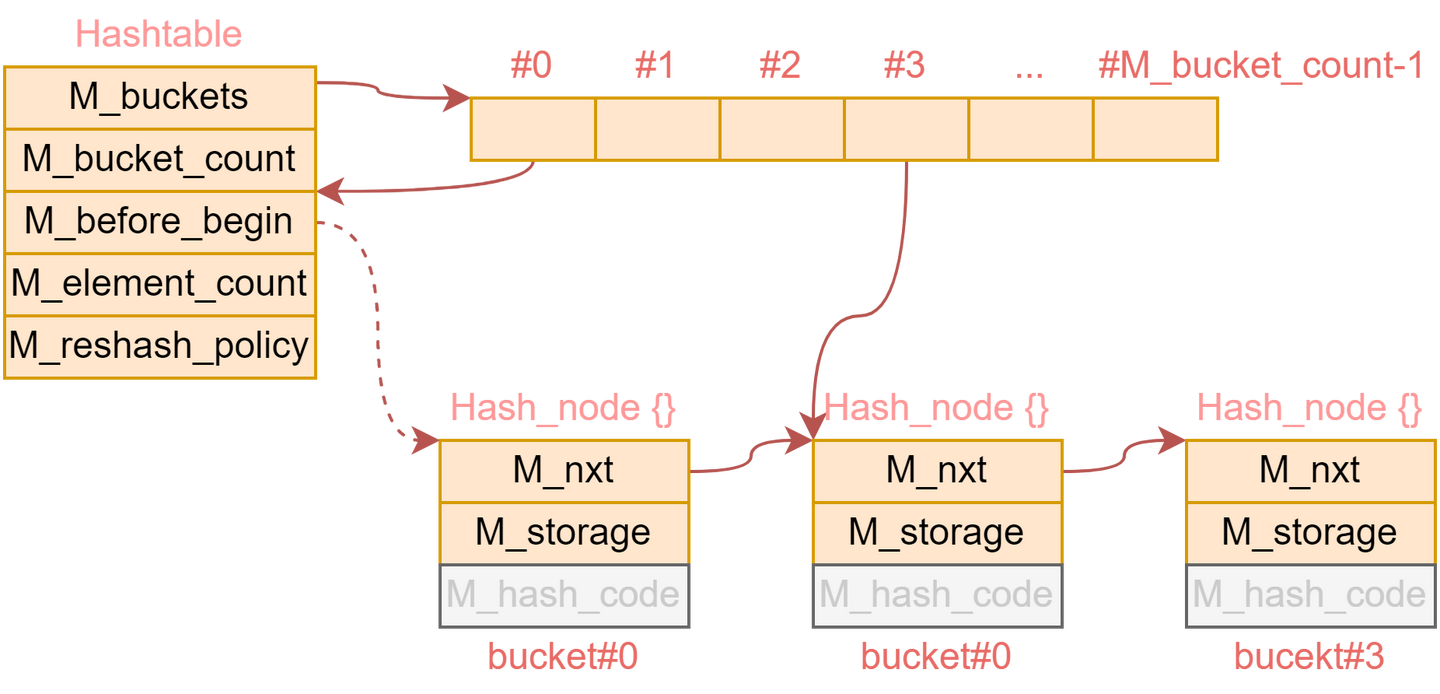
* 每个 _Hashtable 数据结构包含:
* - _Bucket[] _M_buckets
* - _Hash_node_base _M_before_begin
* - size_type _M_bucket_count
* - size_type _M_element_count
*
* 其中 _Bucket 是 _Hash_node_base* 类型,_Hash_node 包含:
* - _Hash_node* _M_next
* - Tp _M_value
* - size_t _M_hash_code(当 __cache_hash_code 为 true 时)
*
* 从标准容器的角度来看,hashtable 相当于:
* - std::forward_list<_Node>,用于存储元素;
* - std::vector<std::forward_list<_Node>::iterator>,用于表示桶。
*
* 非空桶包含指向该桶中第一个节点之前节点的指针。
* 这种设计使得插入时可以实现类似 std::forward_list::insert_after 的操作,
* 删除时可实现 std::forward_list::erase_after 操作。
* _M_before_begin 等价于 std::forward_list::before_begin。
* 空桶则包含 nullptr。
* 需要注意的是,其中一个非空桶会包含 &_M_before_begin,
* 它不是可解引用的节点,因此桶中的节点指针不能被解引用,只能使用它的下一个节点。
*
* 遍历桶中的节点时需要检查哈希码,以确认节点是否仍然属于该桶。
* 这种设计依赖于一个高效的哈希函数,因此建议将 __cache_hash_code 设置为 true。
*
* 容器的迭代器直接由节点构建。
* 这样一来,无论容器中有多少空桶,迭代器的递增操作始终是高效的。
*
* 插入时会计算元素的哈希值,并用它找到对应的桶索引。
* 如果该桶为空,就将元素添加到单向链表的头部,并让该桶指向 _M_before_begin。
* 如果有其他桶原本指向 _M_before_begin,则更新其为新的“前导”节点。
*
* 需要注意:所有等价的值(如果有)都会相邻排列;
* 一旦发现某个值不再等价,后续的节点也不会再是等价的。
*
* 删除操作时,由于迭代器设计简单,需使用哈希函数获取要更新的桶索引。
* 因此当 __cache_hash_code 被设为 false 时,哈希函数必须是 noexcept,
* 并通过 static_assert 强制确保这一点。
*
* 功能通过将实现拆分为多个基类完成,
* 派生类 _Hashtable 被用于 _Map_base、_Insert、_Rehash_base 和 _Equality 等基类中以访问 this 指针。
* _Hashtable_base 被作为非递归的、完全类型的基类使用,以便使用详细的嵌套类型信息,
* 比如迭代器类型和节点类型。
* 这类似于“奇异递归模板模式”(CRTP),但使用的是重构而非显式传递的模板模式。
*
* 使用到的基类模板有:
* - __detail::_Hashtable_base
* - __detail::_Map_base
* - __detail::_Insert
* - __detail::_Rehash_base
* - __detail::_Equality
*/
template<typename _Key, typename _Value, typename _Alloc,
typename _ExtractKey, typename _Equal,
typename _Hash, typename _RangeHash, typename _Unused,
typename _RehashPolicy, typename _Traits>
class _Hashtable
{
}GCC中的哈希表包含多个‘桶’,每个‘桶’是一个链表,同时链表和链表之间又头尾相接,组成一个单链表。
可以理解成这个单链表中的元素是按照哈希值是排序的,而桶指向每一段哈希值相同的片段的头部,用于快速找到节点的位置
Java中使用
链表+红黑树解决哈希冲突,桶里的元素过多时会转化成红黑树,提供保底性能
扩容机制
从键值映射到桶的时间复杂度是O(1),但是在桶中的链表上遍历的时间复杂度是O(n),当插入的元素数量过多时,一些桶里的元素数量会过多,导致查找速度变慢。
GCC中的哈希表默认通过负载因子(元素数量/桶数)来判断是否需要扩容,负载默认阈值是1。
触发扩容后需要:计算新的桶数 → 分配新桶数组 → 按新桶数重哈希并搬迁所有节点 → 释放旧桶数组 → 更新内部状态
默认扩容至少两倍。
c++
/// 默认rehash策略。rehash 策略的默认值。存储桶大小(通常)是
/// 保持负载系数足够小的最小 PRIME。
struct _Prime_rehash_policy
{
_Prime_rehash_policy(float __z = 1.0) noexcept
: _M_max_load_factor(__z), _M_next_resize(0) { }
...
// __n_bkt is current bucket count, __n_elt is current element count,
// and __n_ins is number of elements to be inserted. Do we need to
// increase bucket count? If so, return make_pair(true, n), where n
// is the new bucket count. If not, return make_pair(false, 0).
std::pair<bool, std::size_t>
_M_need_rehash(std::size_t __n_bkt, std::size_t __n_elt,
std::size_t __n_ins) noexcept
{
if (__n_elt + __n_ins > _M_next_resize)
{
// If _M_next_resize is 0 it means that we have nothing allocated so
// far and that we start inserting elements. In this case we start
// with an initial bucket size of 11.
double __min_bkts
= std::max<std::size_t>(__n_elt + __n_ins, _M_next_resize ? 0 : 11)
/ (double)_M_max_load_factor;
if (__min_bkts >= __n_bkt)
return { true,
_M_next_bkt(std::max<std::size_t>(__builtin_floor(__min_bkts) + 1,
__n_bkt * _S_growth_factor)) };
_M_next_resize
= __builtin_floor(__n_bkt * (double)_M_max_load_factor);
return { false, 0 };
}
else
return { false, 0 };
}
...
static const std::size_t _S_growth_factor = 2;
}在每次插入前,都会调用底层的重哈希策略:
cpp
auto __do_rehash
= _M_rehash_policy._M_need_rehash(
_M_bucket_count, // 当前桶数
_M_element_count, // 当前元素数
__n_ins // 本次预计插入的元素数(通常为1)
);该函数的定义(以默认的素数策略 _Prime_rehash_policy 为例)是:
cpp
std::pair<bool, size_t>
_M_need_rehash(size_t __n_bkt, size_t __n_elt, size_t __n_ins) const;- 阈值维护:策略内部维护一个
_M_next_resize,初始为 0。 - 触发条件:当
__n_elt + __n_ins > _M_next_resize时,返回{true, new_bkt},否则{false, 0}。- 首次插入时
_M_next_resize == 0,必然触发; - 之后每次触发后,
_M_next_resize会被更新为floor(current_bkt * max_load_factor)(max_load_factor默认 1.0)
- 首次插入时
触发扩容之后的步骤如下:
计算新桶数
- 计算能容纳
element_count + n_ins个元素的最小桶数:cppsize_t min_bkts = ceil((__n_elt + __n_ins) / max_load_factor); - 与当前桶数乘以增长因子(
_S_growth_factor=2)取最大:cppsize_t hint = max(min_bkts, __n_bkt * _S_growth_factor); - 最终桶数取“大于等于 hint 的最小素数”:cpp
new_buckets = _M_next_bkt(hint); ``` citeturn4view0turn2view0
- 计算能容纳
调用
_M_rehashcppvoid rehash(size_type __n) { // 计算 new_buckets(如上) if (new_buckets != _M_bucket_count) _M_rehash(new_buckets, saved_state); else _M_rehash_policy._M_reset(saved_state); } ``` citeturn2view0在
_M_rehash_aux中搬迁所有节点cpp// 分配新桶数组 __bucket_type* new_arr = _M_allocate_buckets(new_buckets); // 遍历旧桶 for (each bucket i) while (node* p = old_buckets[i]) { old_buckets[i] = p->_M_next; size_t idx = hash_code_of(p) % new_buckets; // 插入到 new_arr[idx] 的链表头或维护等价元素顺序 p->_M_next = new_arr[idx]; new_arr[idx] = p; } // 释放旧桶数组,更新成员 _M_deallocate_buckets(old_buckets, old_count); _M_buckets = new_arr; _M_bucket_count = new_buckets; // 同时更新 _M_begin_bucket_index 以加速 begin() ``` citeturn2view0